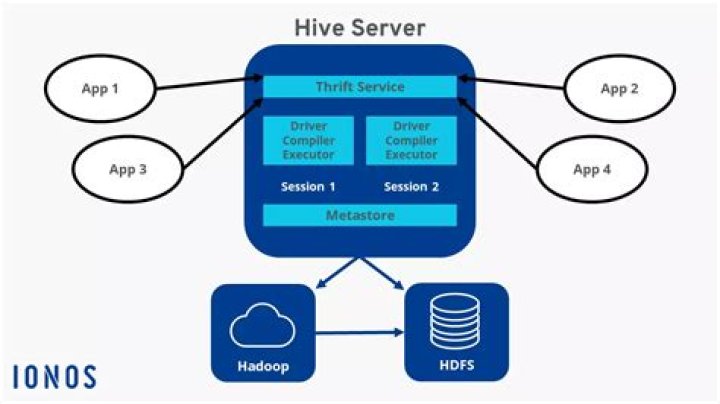
What is hive Mapred mode Nonstrict?

John Castro
Published Feb 15, 2026
What is hive Mapred mode Nonstrict?
In non-strict mode, all partitions are allowed to be dynamic. If your partitioned table is very large, you could block any full table scan queries by putting Hive into strict mode using the set hive. mapred. mode=strict command.
What is the significance of the below line set hive Mapred mode strict?
mapred. mode = strict; It sets the mapreduce jobs to strict mode.By which the queries on partitioned tables can not run without a WHERE clause. This prevents very large job running for long time.
What is Cartesian product in hive?
Cross join, also known as Cartesian product, is a way of joining multiple tables in which all the rows or tuples from one table are paired with the rows and tuples from another table.
When should I use partition in Hive?
Hive Partitions is a way to organizes tables into partitions by dividing tables into different parts based on partition keys. Partition is helpful when the table has one or more Partition keys. Partition keys are basic elements for determining how the data is stored in the table.
Does partition order matter Hive?
1 Answer. Although you’re right about directories being logical constructs, if you consider the amount of metadata your HiveServer2 has to get and sift through in order to execute an average query, the order does matter.
What is Ctrl a delimiter in hive?
The default map key delimiter is a. Ctrl-C character, used to delimit the key and value in a MAP . Rows in a table are delimited. by a newline character.
What is the default execution engine in hive?
Chooses execution engine. Options are: mr (Map Reduce, default), tez (Tez execution, for Hadoop 2 only), or spark (Spark execution, for Hive 1.1. 0 onward). While mr remains the default engine for historical reasons, it is itself a historical engine and is deprecated in the Hive 2 line (HIVE-12300).
What is the difference between Cartesian product and joins?
Cross-join is SQL 99 join and Cartesian product is Oracle Proprietary join. A cross-join that does not have a ‘where’ clause gives the Cartesian product. Cartesian product result-set contains the number of rows in the first table, multiplied by the number of rows in second table.
What happens when you create a Cartesian product?
In terms of SQL, the Cartesian product is a new table formed of two tables. Therefore, each row from the first table joins each row of the second table. You get the multiplication result of two sets making all possible ordered pairs of the original sets’ elements.
What is difference between partition and bucket in Hive?
At a high level, Hive Partition is a way to split the large table into smaller tables based on the values of a column(one partition for each distinct values) whereas Bucket is a technique to divide the data in a manageable form (you can specify how many buckets you want).
What is the difference between bucketing and partitioning?
Partitioning helps in elimination of data, if used in WHERE clause, where as bucketing helps in organizing data in each partition into multiple files, so as same set of data is always written in same bucket.
What is difference between bucketing and partitioning?
Bucketing decomposes data into more manageable or equal parts. With partitioning, there is a possibility that you can create multiple small partitions based on column values. If you go for bucketing, you are restricting number of buckets to store the data. This number is defined during table creation scripts.
What is strict mode in hive?
Hive Strict Mode (hive.mapred.mode=strict) enables hive to restrict certain performance intensive operations.
Why did my hive mapred query return non-strict code?
SET hive.mapred.mode=nonstrict Query returned non-zero code: 1, cause: Cannot modify hive.mapred.mode at runtime. It is in the listof parameters that can’t be modified at runtime
How to use Cartesian product in hive in strict mode?
In strict mode, cartesian product is not allowed. If you really want to perform the operation, set hive.mapred.mode=nonstrict set hive.mapred.mode=nonstrict on top of it. SET hive.mapred.mode=nonstrict Query returned non-zero code: 1, cause: Cannot modify hive.mapred.mode at runtime.
Why does hive global sort take so long to return?
It performs the global sort using only one reducer, so it takes a longer time to return the result. Usage with LIMIT is strongly recommended for ORDER BY. When hive.mapred.mode = strict (by default, hive.mapred.mode = nonstrict) is set and we do not specify LIMIT, there are exceptions.